

Извлечение данных — это процесс сбора определенных данных с веб-страниц. Пользователи могут извлекать текст, изображения, видео, обзоры, продукты и т. д. Вы можете извлекать данные для проведения маркетинговых исследований, анализа настроений, конкурентного анализа и агрегирования данных.
Если вы имеете дело с небольшим объемом данных, вы можете извлечь данные вручную, скопировав конкретную информацию с веб-страниц в электронную таблицу или формат документа по своему вкусу. Например, если вы как клиент ищете отзывы в Интернете, чтобы помочь вам принять решение о покупке, вы можете удалить данные вручную.
С другой стороны, если вы имеете дело с большими наборами данных, вам нужен метод автоматического извлечения данных. Вы можете создать собственное решение для извлечения данных или использовать для таких задач Proxy API или Scraping API.
Однако эти методы могут быть менее эффективными, поскольку некоторые из целевых сайтов могут быть защищены капчами. Возможно, вам также придется управлять ботами и прокси. Такие задачи могут отнимать у вас много времени и ограничивать характер контента, который вы можете извлечь.
Оглавление
Парсинг браузера: решение
Вы можете преодолеть все эти проблемы с помощью браузера Scraping от Bright Data. Этот универсальный браузер помогает собирать данные с веб-сайтов, которые трудно очистить. Это браузер, который использует графический интерфейс пользователя (GUI) и управляется Puppeteer или Playwright API, что делает его незаметным для ботов.
Scraping Browser имеет встроенные функции разблокировки, которые автоматически обрабатывают все блокировки от вашего имени. Браузер открывается на серверах Bright Data, а это означает, что вам не нужна дорогостоящая внутренняя инфраструктура для удаления данных для ваших крупномасштабных проектов.
Особенности браузера Bright Data Scraping
- Автоматическая разблокировка веб-сайтов: вам не нужно постоянно обновлять браузер, так как этот браузер автоматически настраивается для решения CAPTCHA, новых блоков, отпечатков пальцев и повторных попыток. Скрапинг Браузер имитирует реального пользователя.
- Большая прокси-сеть: вы можете настроить таргетинг на любую страну, которую хотите, так как Scraping Browser имеет более 72 миллионов IP-адресов. Вы можете настроить таргетинг на города или даже на операторов связи и воспользоваться преимуществами лучших в своем классе технологий.
- Масштабируемость: вы можете открывать тысячи сеансов одновременно, поскольку этот браузер использует инфраструктуру Bright Data для обработки всех запросов.
- Совместимость с Puppeteer и Playwright: этот браузер позволяет вам выполнять вызовы API и получать любое количество сеансов браузера, используя Puppeteer (Python) или Playwright (Node.js).
- Экономит время и ресурсы: вместо того, чтобы настраивать прокси, обо всем позаботится обо всем в фоновом режиме Scraping Browser. Вам также не нужно настраивать внутреннюю инфраструктуру, так как этот инструмент позаботится обо всем в фоновом режиме.
Как настроить парсинг браузера
- Перейдите на веб-сайт Bright Data и нажмите «Браузер парсинга» на вкладке «Решения парсинга».
- Завести аккаунт. Вы увидите два варианта; «Начать бесплатную пробную версию» и «Начать бесплатно с Google». Давайте сейчас выберем «Начать бесплатную пробную версию» и перейдем к следующему шагу. Вы можете создать учетную запись вручную или использовать свою учетную запись Google.
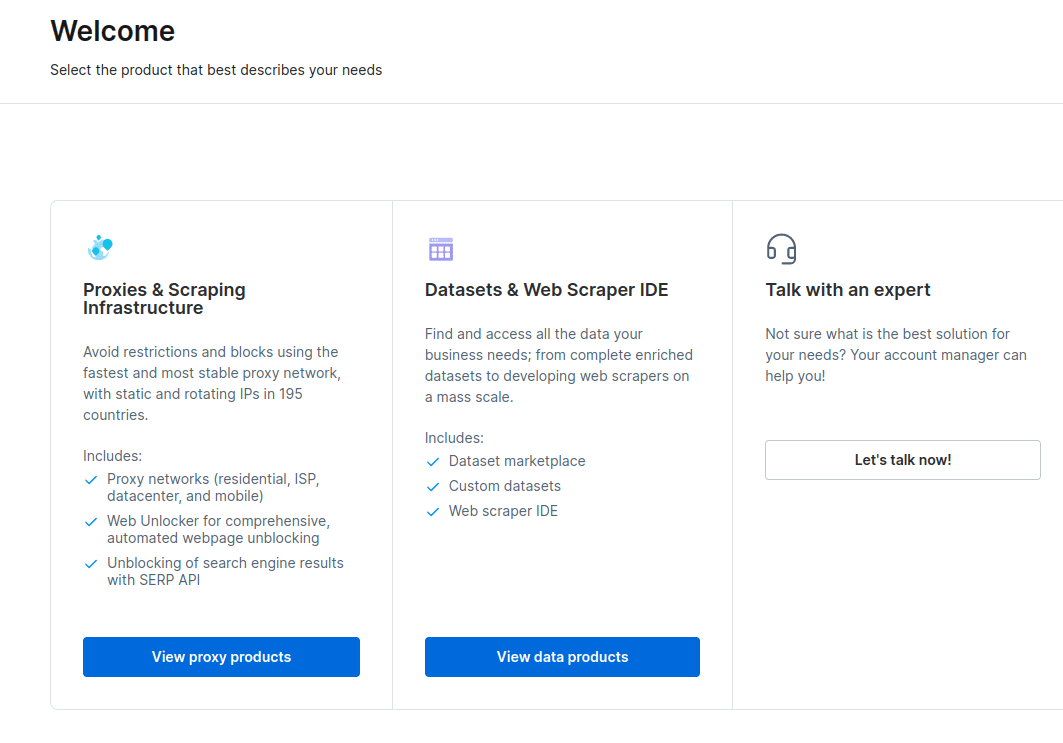
- Когда ваша учетная запись будет создана, на панели инструментов будет представлено несколько вариантов. Выберите «Прокси и инфраструктура парсинга».
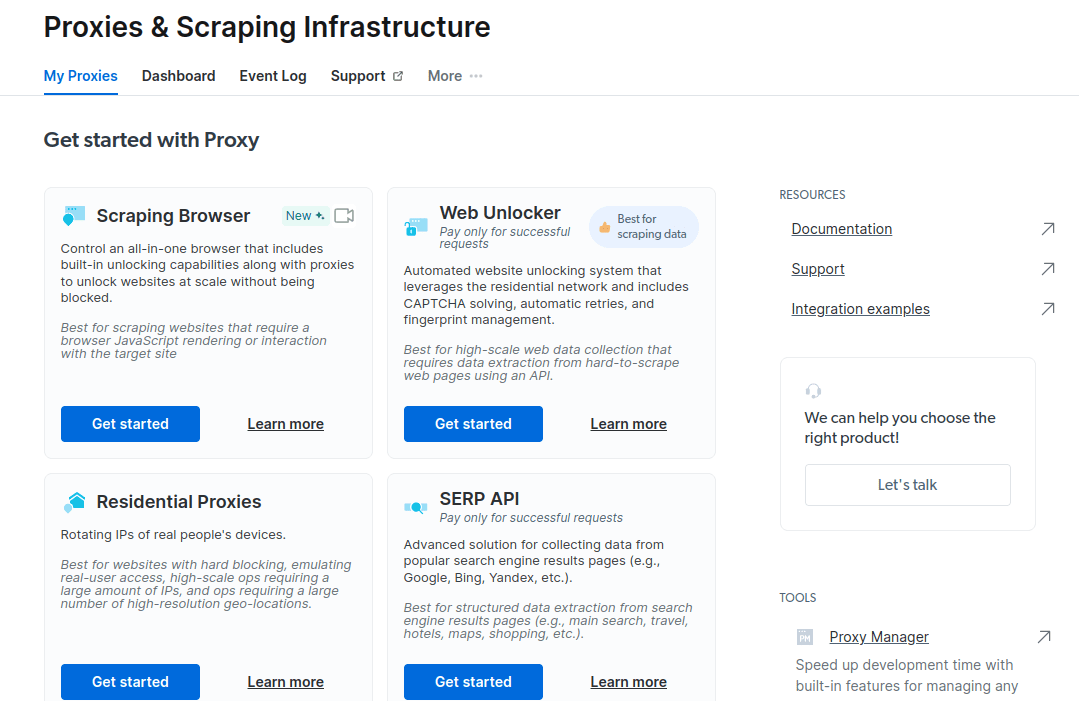
- В открывшемся новом окне выберите Scraping Browser и нажмите «Начать».
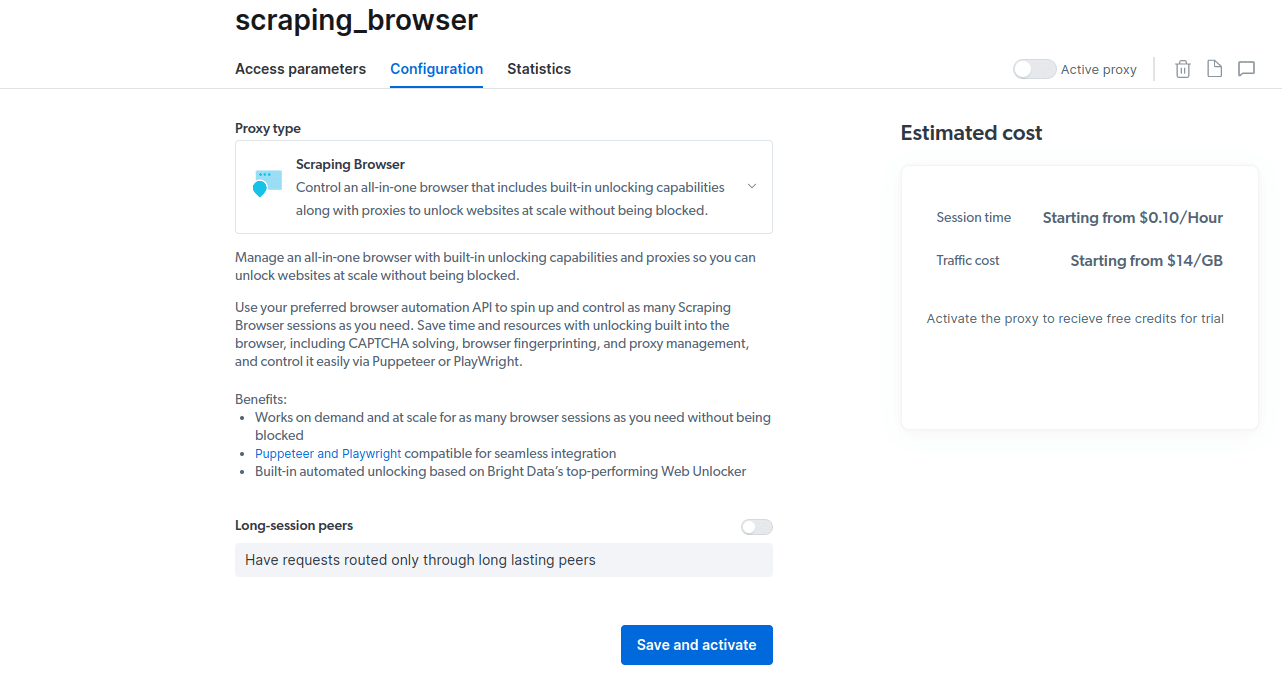
- Сохраните и активируйте свои конфигурации.
- Активируйте бесплатную пробную версию. Первый вариант дает вам кредит в размере 5 долларов, который вы можете использовать для использования прокси-сервера. Нажмите на первый вариант, чтобы попробовать этот продукт. Однако, если вы активный пользователь, вы можете нажать на второй вариант, который дает вам 50 долларов бесплатно, если вы загружаете свою учетную запись на 50 долларов или более.
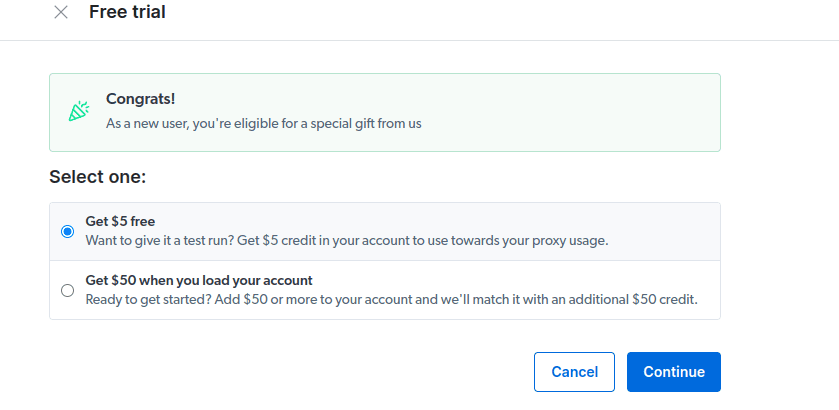
- Введите платежную информацию. Не волнуйтесь, платформа ничего с вас не возьмет. Платежная информация просто подтверждает, что вы новый пользователь и не ищете халявы, создавая несколько учетных записей.
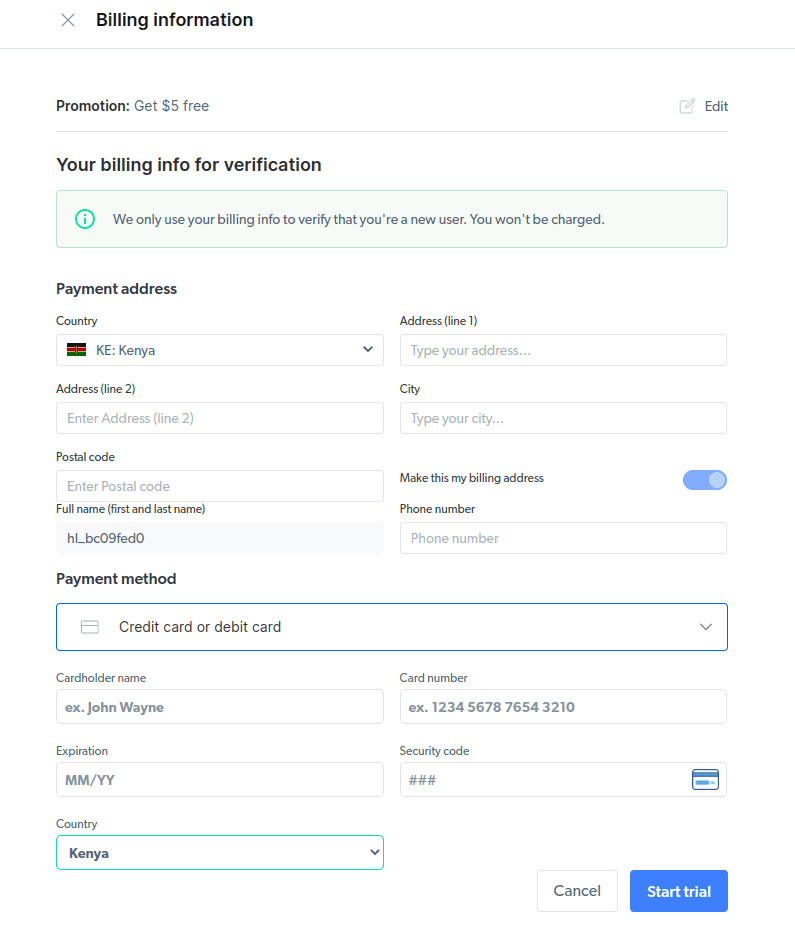
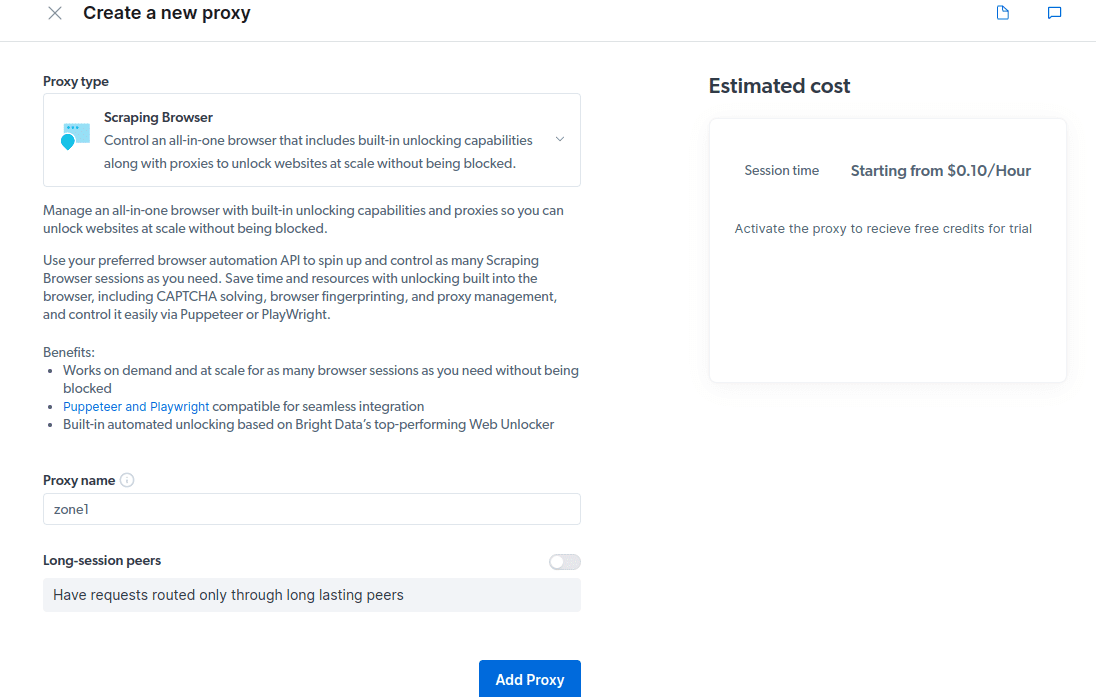
- Создайте новый прокси. После того, как вы сохранили свои платежные данные, вы можете создать новый прокси. Нажмите значок «Добавить» и выберите Scraping Browser в качестве «типа прокси». Нажмите «Добавить прокси» и перейдите к следующему шагу.
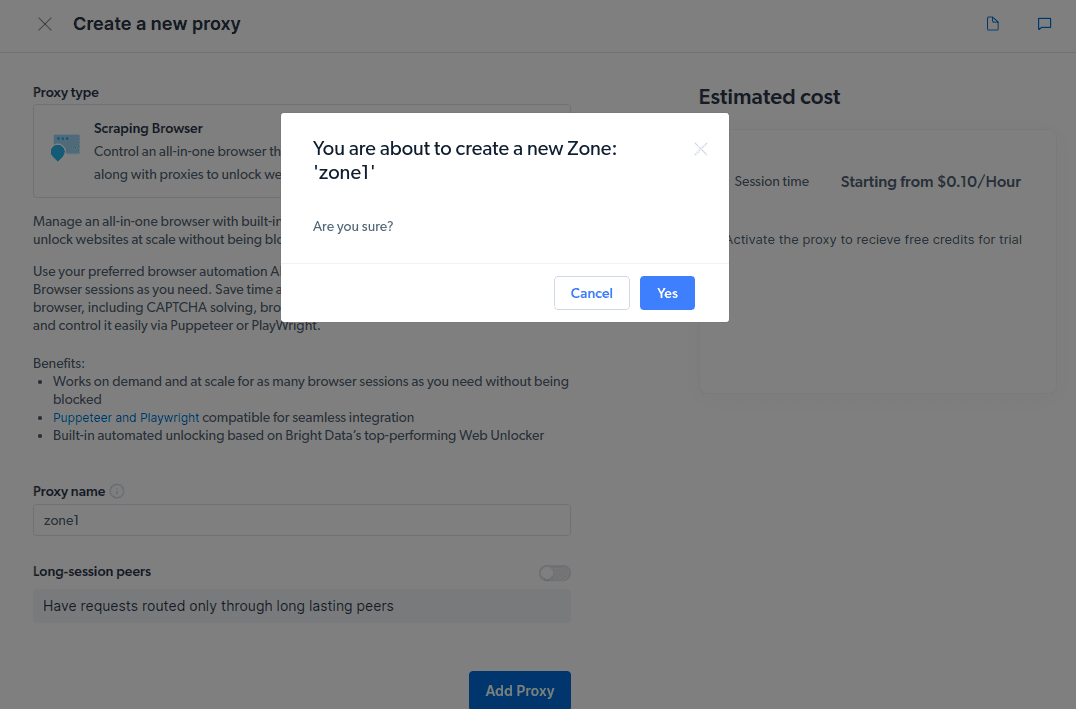
- Создайте новую «зону». Появится всплывающее окно с вопросом, хотите ли вы создать новую зону; нажмите «Да» и продолжите.
- Нажмите «Проверить код и примеры интеграции». Теперь вы получите примеры интеграции прокси, которые вы можете использовать для удаления данных с вашего целевого веб-сайта. Вы можете использовать Node.js или Python для извлечения данных с вашего целевого веб-сайта.
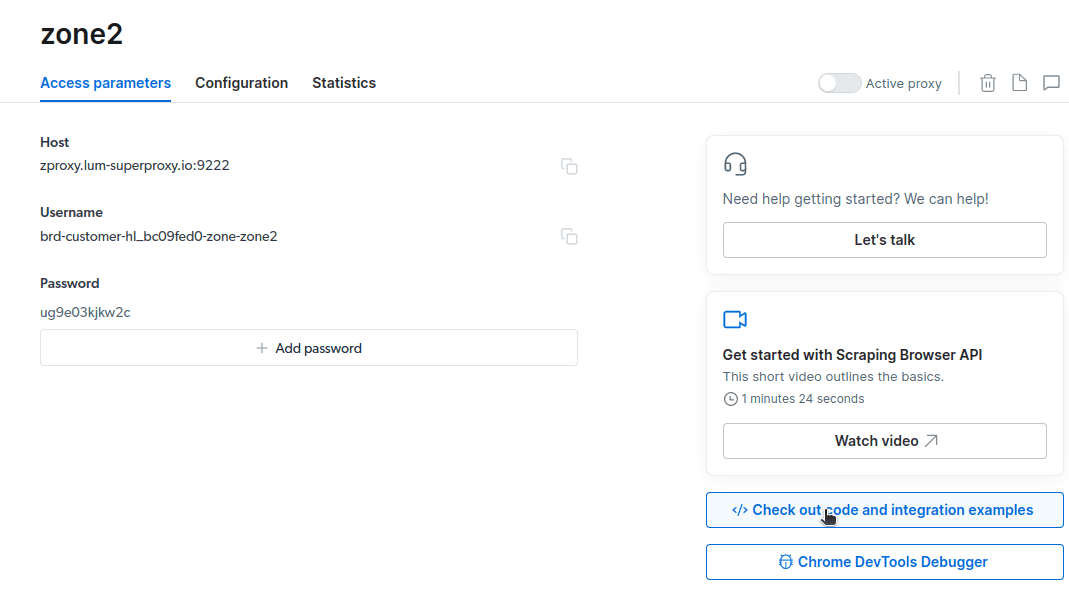
Теперь у вас есть все необходимое для извлечения данных с веб-сайта. Мы воспользуемся нашим веб-сайтом toadmin.ru.com, чтобы продемонстрировать, как работает Scraping Browser. Для этой демонстрации мы будем использовать node.js. Вы можете продолжить, если у вас установлен node.js.
Следуй этим шагам;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
Я изменю свой код в строке 10 следующим образом:
await page.goto(‘https://toadmin.ru.com/authors/‘);
Мой окончательный код теперь будет;
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://toadmin.ru.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
node script.js
У вас будет что-то подобное на вашем терминале
Как экспортировать данные
Вы можете использовать несколько подходов для экспорта данных, в зависимости от того, как вы собираетесь их использовать. Сегодня мы можем экспортировать данные в html-файл, изменив сценарий для создания нового файла с именем data.html вместо того, чтобы печатать его на консоли.
Вы можете изменить содержимое своего кода следующим образом;
const puppeteer = require('puppeteer-core');
const fs = require('fs');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://toadmin.ru.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
// Write HTML content to a file
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
Теперь вы можете запустить код с помощью этой команды;
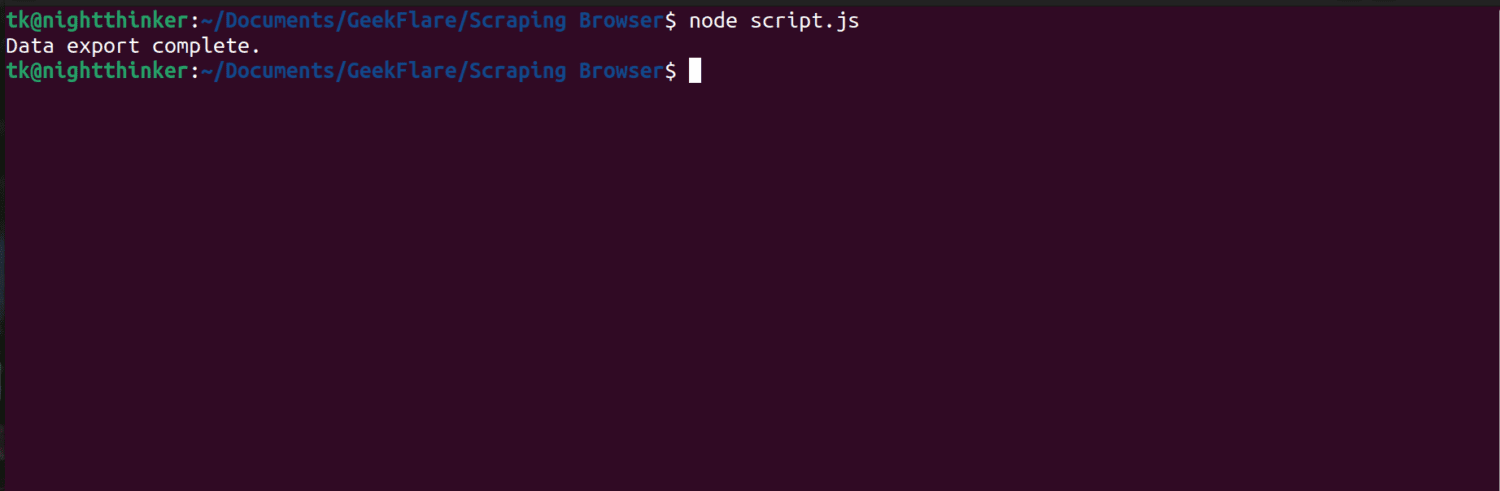
node script.js
Как вы можете видеть на следующем снимке экрана, терминал отображает сообщение «Экспорт данных завершен».
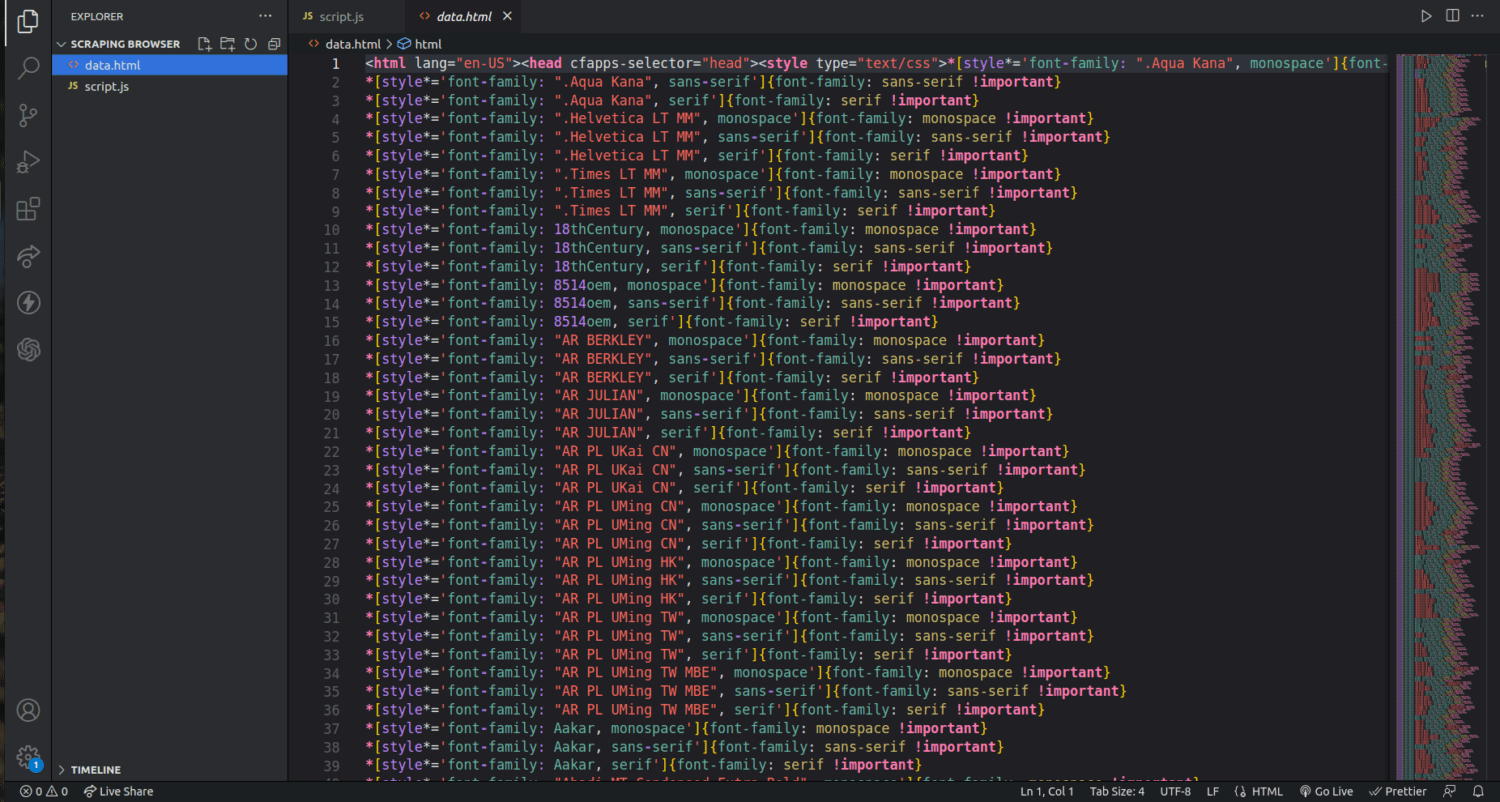
Если мы проверим папку нашего проекта, мы увидим файл с именем data.html с тысячами строк кода.
Я только что коснулся того, как извлекать данные с помощью браузера Scraping. С помощью этого инструмента я могу даже сузить и удалить только имена авторов и их описания.
Если вы хотите использовать Scraping Browser, определите наборы данных, которые вы хотите извлечь, и соответствующим образом измените код. Вы можете извлекать текст, изображения, видео, метаданные и ссылки в зависимости от целевого веб-сайта и структуры HTML-файла.
Часто задаваемые вопросы
Законно ли извлечение данных и веб-скрапинг?
Веб-скрапинг — спорная тема: одни говорят, что это аморально, а другие считают, что это нормально. Законность веб-скрапинга будет зависеть от характера очищаемого контента и политики целевой веб-страницы.
Как правило, удаление данных с личной информацией, такой как адреса и финансовые данные, считается незаконным. Прежде чем собирать данные, проверьте, есть ли на сайте, на который вы ориентируетесь, какие-либо рекомендации. Всегда следите за тем, чтобы вы не удаляли те данные, которые не являются общедоступными.
Является ли Scraping Browser бесплатным инструментом?
Нет. Парсинг браузера — это платная услуга. Если вы подписываетесь на бесплатную пробную версию, инструмент дает вам кредит в размере 5 долларов. Платные пакеты начинаются с 15 долларов США за ГБ + 0,1 доллара США в час. Вы также можете выбрать вариант оплаты по мере использования, который начинается с 20 долларов США за ГБ + 0,1 доллара США в час.
В чем разница между парсинг-браузерами и безголовыми браузерами?
Scraping Browser — это навороченный браузер, а это означает, что он имеет графический интерфейс пользователя (GUI). С другой стороны, безголовые браузеры не имеют графического интерфейса. Безголовые браузеры, такие как Selenium, используются для автоматизации парсинга веб-страниц, но иногда их возможности ограничены, поскольку им приходится иметь дело с CAPTCHA и обнаружением ботов.
Подведение итогов
Как видите, Scraping Browser упрощает извлечение данных с веб-страниц. Scraping Browser прост в использовании по сравнению с такими инструментами, как Selenium. Даже не разработчики могут использовать этот браузер с потрясающим пользовательским интерфейсом и хорошей документацией. Инструмент имеет возможности разблокировки, недоступные в других инструментах очистки, что делает его эффективным для всех, кто хочет автоматизировать такие процессы.
Вы также можете узнать, как запретить плагинам ChatGPT очищать содержимое вашего веб-сайта.