

В этой статье упоминаются и разъясняются некоторые из лучших библиотек Python для специалистов по данным и команды машинного обучения.
Python — идеальный язык, широко используемый в этих двух областях, в основном из-за предлагаемых им библиотек.
Это связано с приложениями библиотек Python, такими как ввод/вывод данных, ввод-вывод и анализ данных, а также другими операциями по обработке данных, которые специалисты по данным и специалисты по машинному обучению используют для обработки и исследования данных.
Оглавление
Библиотеки Python, что это такое?
Библиотека Python — это обширная коллекция встроенных модулей, содержащих предварительно скомпилированный код, включая классы и методы, что избавляет разработчика от необходимости реализовывать код с нуля.
Важность Python в науке о данных и машинном обучении
Python имеет лучшие библиотеки для использования экспертами по машинному обучению и науке о данных.
Его синтаксис прост, что делает его эффективным для реализации сложных алгоритмов машинного обучения. Кроме того, простой синтаксис сокращает кривую обучения и облегчает понимание.
Python также поддерживает быструю разработку прототипов и гладкое тестирование приложений.
Большое сообщество Python удобно для ученых, занимающихся данными, которые при необходимости могут легко найти решения для своих запросов.
Насколько полезны библиотеки Python?
Библиотеки Python играют важную роль в создании приложений и моделей для машинного обучения и науки о данных.
Эти библиотеки помогают разработчику повторно использовать код. Таким образом, вы можете импортировать соответствующую библиотеку, которая реализует определенную функцию в вашей программе, не изобретая велосипед.
Библиотеки Python, используемые в машинном обучении и науке о данных
Эксперты по науке о данных рекомендуют различные библиотеки Python, с которыми должны быть знакомы энтузиасты науки о данных. В зависимости от их значимости в приложении эксперты по машинному обучению и науке о данных применяют различные библиотеки Python, разделенные на библиотеки, для развертывания моделей, извлечения и извлечения данных, обработки данных и визуализации данных.
В этой статье описаны некоторые часто используемые библиотеки Python в науке о данных и машинном обучении.
Давайте посмотрим на них сейчас.
Нампи
Библиотека Numpy Python, а также полный числовой код Python, построена с использованием хорошо оптимизированного кода C. Специалисты по данным предпочитают его за глубокие математические расчеты и научные расчеты.
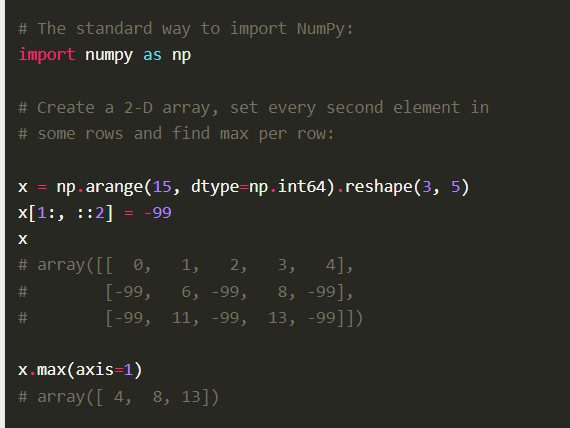
Функции
Numpy поставляется с другими комплексными функциями, такими как векторизация математических операций, индексация и ключевые концепции реализации массивов и матриц.
Панды
Pandas — известная библиотека машинного обучения, предоставляющая высокоуровневые структуры данных и многочисленные инструменты для простого и эффективного анализа массивных наборов данных. С очень небольшим количеством команд эта библиотека может преобразовывать сложные операции с данными.
Многочисленные встроенные методы, которые могут группировать, индексировать, извлекать, разделять, реструктурировать данные и фильтровать наборы перед их вставкой в одномерные и многомерные таблицы; составляет эту библиотеку.
Основные возможности библиотеки Pandas
Он очень эффективен благодаря хорошей функциональности анализа данных и высокой гибкости.
Матплотлиб
2D-графическая библиотека Python Matplotlib может легко обрабатывать данные из многочисленных источников. Визуализации, которые он создает, являются статическими, анимированными и интерактивными, которые пользователь может увеличивать, что делает его эффективным для визуализации и создания диаграмм. Он также позволяет настраивать макет и визуальный стиль.
Его документация имеет открытый исходный код и предлагает обширный набор инструментов, необходимых для реализации.
Matplotlib импортирует вспомогательные классы для реализации года, месяца, дня и недели, что позволяет эффективно манипулировать данными временных рядов.
Scikit-learn
Если вы рассматриваете библиотеку, которая поможет вам работать со сложными данными, Scikit-learn должна стать вашей идеальной библиотекой. Специалисты по машинному обучению широко используют Scikit-learn. Библиотека связана с другими библиотеками, такими как NumPy, SciPy и matplotlib. Он предлагает как контролируемые, так и неконтролируемые алгоритмы обучения, которые можно использовать для производственных приложений.

Особенности библиотеки Scikit-learn Python
Библиотека Scikit-learn эффективна при извлечении признаков из наборов данных текста и изображений. Кроме того, можно проверить точность контролируемых моделей на невидимых данных. Его многочисленные доступные алгоритмы делают возможным интеллектуальный анализ данных и другие задачи машинного обучения.
SciPy
SciPy (Scientific Python Code) — это библиотека машинного обучения, которая предоставляет модули, применяемые к математическим функциям и алгоритмам, которые широко применимы. Его алгоритмы решают алгебраические уравнения, интерполяцию, оптимизацию, статистику и интегрирование.
Его главной особенностью является расширение NumPy, которое добавляет инструменты для решения математических функций и предоставляет структуры данных, такие как разреженные матрицы.
SciPy использует высокоуровневые команды и классы для обработки и визуализации данных. Его системы обработки данных и прототипы делают его еще более эффективным инструментом.
Более того, высокоуровневый синтаксис SciPy упрощает использование программистами с любым уровнем опыта.
Единственным недостатком SciPy является то, что он сосредоточен исключительно на числовых объектах и алгоритмах; поэтому не может предложить какую-либо функцию построения графиков.
ПиТорч
Эта разнообразная библиотека машинного обучения эффективно реализует тензорные вычисления с ускорением графического процессора, создавая динамические вычислительные графики и автоматические вычисления градиентов. Библиотека Torch, библиотека машинного обучения с открытым исходным кодом, разработанная на C, создает библиотеку PyTorch.

Ключевые особенности включают в себя:
Вы можете использовать PyTorch при разработке приложений НЛП.
Керас
Keras — это библиотека Python для машинного обучения с открытым исходным кодом, используемая для экспериментов с глубокими нейронными сетями.
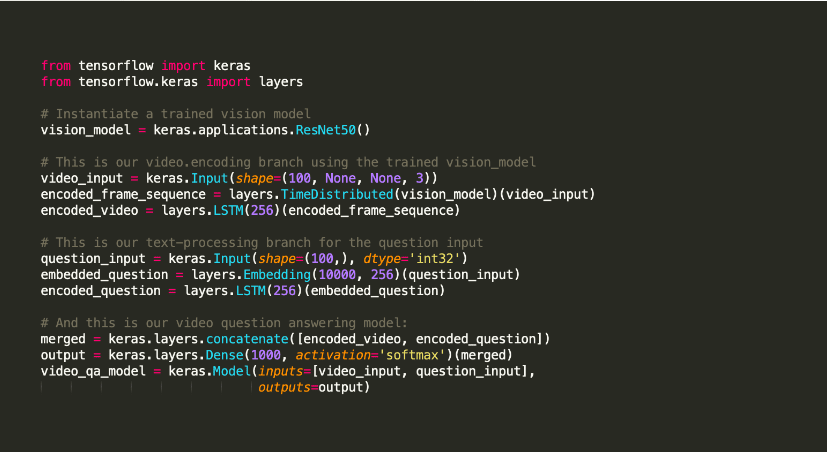
Он известен тем, что предлагает утилиты, которые поддерживают такие задачи, как компиляция моделей и визуализация графиков, среди прочего. Он применяет Tensorflow для своего бэкэнда. В качестве альтернативы вы можете использовать Theano или нейронные сети, такие как CNTK, в бэкэнде. Эта внутренняя инфраструктура помогает ему создавать вычислительные графы, используемые для выполнения операций.
Основные возможности библиотеки
Приложения Keras включают в себя строительные блоки нейронной сети, такие как слои и цели, а также другие инструменты, облегчающие работу с изображениями и текстовыми данными.
Сиборн
Seaborn — еще один ценный инструмент для визуализации статистических данных.
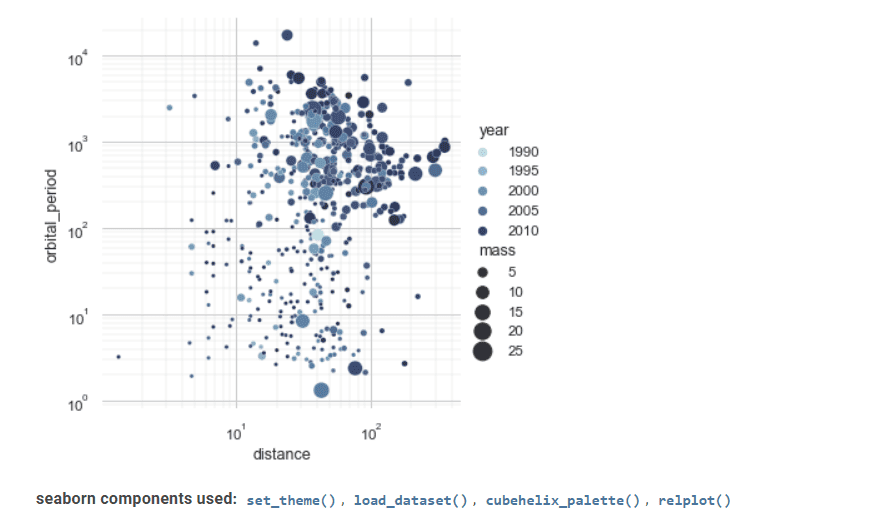
Его продвинутый интерфейс позволяет реализовать привлекательные и информативные статистические графические рисунки.
сюжетно
Plotly — это веб-инструмент для трехмерной визуализации, созданный на основе библиотеки Plotly JS. Он имеет широкую поддержку различных типов диаграмм, таких как линейные диаграммы, точечные диаграммы и спарклайны блочного типа.
Его приложение включает в себя создание веб-визуализации данных в блокнотах Jupyter.
Plotly подходит для визуализации, потому что он может указать на выбросы или аномалии на графике с помощью инструмента наведения. Вы также можете настроить графики в соответствии с вашими предпочтениями.
Недостатком Plotly является то, что его документация устарела; поэтому использование его в качестве руководства может быть затруднено для пользователя. Кроме того, он имеет множество инструментов, которые пользователь должен изучить. Уследить за всеми может быть сложно.
Особенности библиотеки Plotly Python
SimpleITK
SimpleITK — это библиотека анализа изображений, которая предлагает интерфейс для Insight Toolkit (ITK). Он основан на C++ и имеет открытый исходный код.
Особенности библиотеки SimpleITK
Его упрощенный интерфейс доступен на различных языках программирования, таких как R, C#, C++, Java и Python.
Статистическая модель
Statsmodel оценивает статистические модели, реализует статистические тесты и исследует статистические данные с помощью классов и функций.
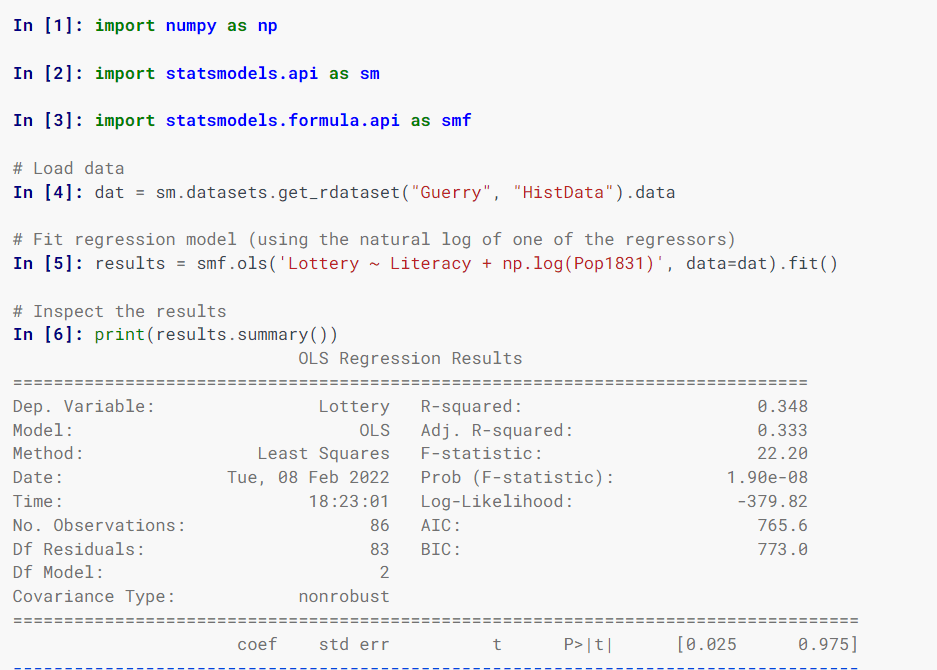
Для указания моделей используются формулы в стиле R, массивы NumPy и фреймы данных Pandas.
Скрапи
Этот пакет с открытым исходным кодом является предпочтительным инструментом для извлечения (очистки) и сканирования данных с веб-сайта. Он асинхронный и, следовательно, относительно быстрый. Scrapy имеет архитектуру и функции, которые делают его эффективным.
С другой стороны, его установка отличается для разных операционных систем. Кроме того, вы не можете использовать его на сайтах, созданных на JS. Кроме того, он может работать только с Python 2.7 или более поздними версиями.
Специалисты по науке о данных применяют его в интеллектуальном анализе данных и автоматизированном тестировании.
Функции
Подушка
Pillow — это библиотека изображений Python, которая манипулирует и обрабатывает изображения.
Он добавляет к функциям обработки изображений интерпретатора Python, поддерживает различные форматы файлов и предлагает отличное внутреннее представление.
К данным, хранящимся в основных форматах файлов, можно легко получить доступ благодаря Pillow.
Подведение итогов💃
Это подводит итог нашему исследованию некоторых из лучших библиотек Python для специалистов по данным и специалистов по машинному обучению.
Как показано в этой статье, у Python есть более полезные пакеты для машинного обучения и обработки данных. В Python есть и другие библиотеки, которые вы можете применять в других областях.
Возможно, вы захотите узнать о некоторых из лучших блокнотов по науке о данных.
Приятного обучения!