
Команда Linux uniq просматривает ваши текстовые файлы в поисках уникальных или повторяющихся строк. В этом руководстве мы расскажем о ее универсальности и функциях, а также о том, как вы можете максимально использовать эту замечательную утилиту.
Оглавление
Поиск совпадающих строк текста в Linux
Команда uniq быстро, гибко и отлично умеет. Однако, как и многие команды Linux, у него есть несколько причуд, и это нормально, если вы о них знаете. Если вы сделаете решительный шаг, не обладая знаниями изнутри, вы вполне можете остаться ломать голову над результатами. Мы будем указывать на эти причуды по ходу дела.
Команда uniq идеальна для тех, кто находится в лагере целеустремленных, спроектированных так, чтобы делать одно дело и делать это хорошо. Вот почему он также особенно хорошо подходит для работы с конвейерами и играет свою роль в конвейерах команд. Один из его наиболее частые соавторы это sort, потому что uniq должен иметь отсортированный ввод для работы.
Зажигаем!
Запуск uniq без параметров
У нас есть текстовый файл со словами к Роберт Джонсон песня Я верю, что вытираю свою метлу. Посмотрим, что из этого делает uniq.
Мы введем следующее, чтобы преобразовать вывод в less:
uniq dust-my-broom.txt | less

Мы получаем всю песню, включая повторяющиеся строки, меньше:

Это не похоже ни на уникальные, ни на повторяющиеся строки.
Верно — потому что это первая причуда. Если вы запустите uniq без параметров, он будет вести себя так, как если бы вы использовали параметр -u (уникальные строки). Это указывает uniq на печать только уникальных строк из файла. Причина, по которой вы видите повторяющиеся строки, заключается в том, что для того, чтобы uniq считал строку дубликатом, она должна быть смежной с ее дубликатом, и именно здесь применяется сортировка.
Когда мы сортируем файл, он группирует повторяющиеся строки, и uniq рассматривает их как дубликаты. Мы будем использовать sort для файла, направить отсортированный вывод в uniq, а затем направить окончательный вывод в less.
Для этого мы набираем следующее:
sort dust-my-broom.txt | uniq | less

Отсортированный список строк отображается меньше.

Строка «Я думаю, что вытираю пыль со своей метлы» определенно встречается в песне не раз. Фактически, это повторяется дважды в первых четырех строках песни.
Итак, почему он отображается в списке уникальных строк? Поскольку в первый раз в файле появляется строка, она уникальна; дублируются только последующие записи. Вы можете думать об этом как о перечислении первого появления каждой уникальной строки.
Давайте снова воспользуемся сортировкой и перенаправим вывод в новый файл. Таким образом, нам не нужно использовать сортировку в каждой команде.
Набираем следующую команду:
sort dust-my-broom.txt > sorted.txt
 sorted.txt »в окне терминала. ‘ width = ”646 ″ height =” 57 ″ onload = ”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this);» onerror = ”this.onerror = null; pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this);”>
sorted.txt »в окне терминала. ‘ width = ”646 ″ height =” 57 ″ onload = ”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this);» onerror = ”this.onerror = null; pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this);”>
Теперь у нас есть предварительно отсортированный файл для работы.
Подсчет дубликатов
Вы можете использовать опцию -c (count), чтобы напечатать, сколько раз каждая строка появляется в файле.
Введите следующую команду:
uniq -c sorted.txt | less

Каждая строка начинается с того, сколько раз эта строка появляется в файле. Однако вы заметите, что первая строка пуста. Это говорит о том, что в файле пять пустых строк.
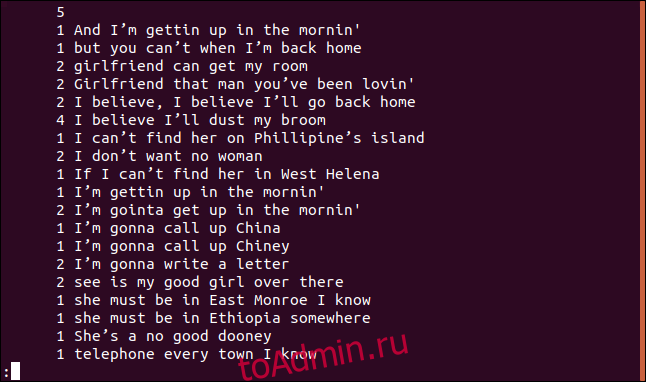
Если вы хотите, чтобы вывод был отсортирован в числовом порядке, вы можете передать вывод uniq в sort. В нашем примере мы будем использовать параметры -r (обратный) и -n (числовая сортировка) и направить результаты в less.
Набираем следующее:
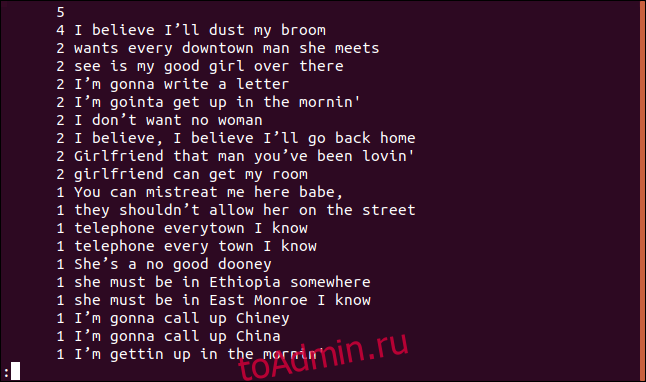
uniq -c sorted.txt | sort -rn | less

Список отсортирован по убыванию в зависимости от частоты появления каждой строки.
Список только повторяющихся строк
Если вы хотите видеть только те строки, которые повторяются в файле, вы можете использовать параметр -d (повторение). Независимо от того, сколько раз строка дублируется в файле, она указывается только один раз.
Чтобы использовать эту опцию, мы вводим следующее:
uniq -d sorted.txt

Дублированные строки перечислены для нас. Вы заметите пустую строку вверху, что означает, что файл содержит повторяющиеся пустые строки — это не пространство, оставленное uniq для косметического смещения списка.

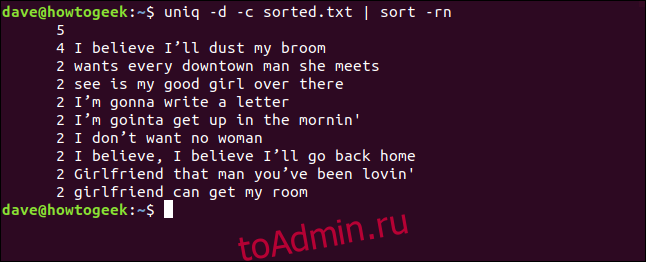
Мы также можем комбинировать параметры -d (повторение) и -c (количество) и направлять вывод через сортировку. Это дает нам отсортированный список строк, которые появляются как минимум дважды.
Введите следующее, чтобы использовать эту опцию:
uniq -d -c sorted.txt | sort -rn
Список всех повторяющихся строк
Если вы хотите видеть список каждой повторяющейся строки, а также запись для каждого раза, когда строка появляется в файле, вы можете использовать параметр -D (все повторяющиеся строки).
Чтобы использовать эту опцию, вы вводите следующее:
uniq -D sorted.txt | less

Список содержит запись для каждой повторяющейся строки.

Если вы используете параметр –group, он печатает каждую повторяющуюся строку с пустой строкой либо до (добавление), либо после каждой группы (добавление), либо и до, и после (обе) каждой группы.
Мы используем append в качестве модификатора, поэтому набираем следующее:
uniq --group=append sorted.txt | less

Группы разделены пустыми строками, чтобы их было легче читать.

Проверка определенного количества символов
По умолчанию uniq проверяет всю длину каждой строки. Однако, если вы хотите ограничить проверки определенным количеством символов, вы можете использовать параметр -w (проверять символы).
В этом примере мы повторим последнюю команду, но ограничим сравнения первыми тремя символами. Для этого набираем следующую команду:
uniq -w 3 --group=append sorted.txt | less

Мы получаем совершенно разные результаты и группировки.

Все строки, начинающиеся с «I b», сгруппированы вместе, потому что эти части строк идентичны, поэтому они считаются дубликатами.
Точно так же все строки, начинающиеся с «Я», обрабатываются как дубликаты, даже если остальной текст отличается.
Игнорирование определенного количества символов
В некоторых случаях может быть полезно пропустить определенное количество символов в начале каждой строки, например, когда строки в файле нумеруются. Или, скажем, вам нужно uniq, чтобы перепрыгнуть через метку времени и начать проверку строк с шестого символа, а не с первого символа.
Ниже представлена версия нашего отсортированного файла с пронумерованными строками.
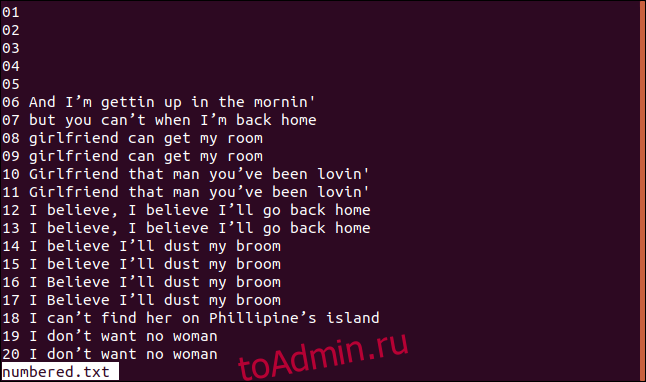
Если мы хотим, чтобы uniq начинал свои проверки сравнения с третьего символа, мы можем использовать параметр -s (пропустить символы), набрав следующее:
uniq -s 3 -d -c numbered.txt

Линии распознаются как дубликаты и подсчитываются правильно. Обратите внимание, что номера отображаемых строк соответствуют первому появлению каждого дубликата.
Вы также можете пропускать поля (последовательность символов и некоторое количество пробелов) вместо символов. Мы будем использовать параметр -f (поля), чтобы указать uniq, какие поля игнорировать.
Мы вводим следующее, чтобы указать uniq игнорировать первое поле:
uniq -f 1 -d -c numbered.txt
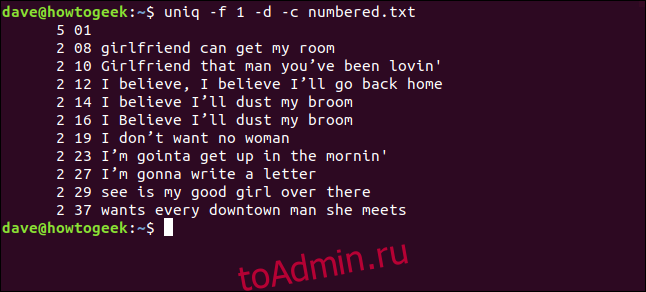
Мы получили те же результаты, что и когда сказали uniq пропустить три символа в начале каждой строки.
Игнорирование дела
По умолчанию uniq чувствителен к регистру. Если одна и та же буква отображается в верхнем регистре и в нижнем регистре, uniq считает, что строки разные.
Например, посмотрите вывод следующей команды:
uniq -d -c sorted.txt | sort -rn

Строки «Я верю, что вытираю пыль со своей метлы» и «Я считаю, что вытираю пыль со своей метлы» не рассматриваются как дубликаты из-за разницы в регистре букв «B» в «верю».
Если мы включим параметр -i (игнорировать регистр), эти строки будут рассматриваться как дубликаты. Набираем следующее:
uniq -d -c -i sorted.txt | sort -rn
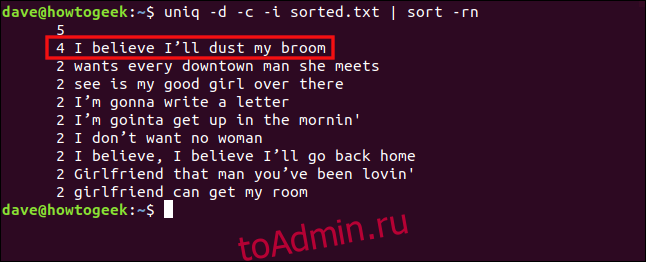
Теперь строки обрабатываются как дубликаты и сгруппированы вместе.
Linux предоставляет в ваше распоряжение множество специальных утилит. Как и многие из них, uniq — не инструмент, которым вы будете пользоваться каждый день.
Вот почему большая часть опыта работы с Linux заключается в том, чтобы помнить, какой инструмент решит вашу текущую проблему и где вы можете снова его найти. Однако, если вы будете практиковаться, у вас все будет хорошо.
Или вы всегда можете просто поискать toadmin.ru — у нас, вероятно, есть статья об этом.