

Команда grep в Linux — это утилита сопоставления строк и шаблонов, которая отображает совпадающие строки из нескольких файлов. Он также работает с конвейерным выводом других команд. Мы покажем вам, как это сделать.
Оглавление
История grep
Команда grep известна в Linux и Unix круги по трем причинам. Во-первых, это чрезвычайно полезно. Во-вторых, множество вариантов может быть ошеломляющим. В-третьих, он был написан в одночасье для удовлетворения конкретной потребности. Первые два удачливы; третий немного выключен.
Кен Томпсон извлек возможности поиска по регулярным выражениям из редактора ed (произносится и-ди) и создал небольшую программу для собственного использования для поиска в текстовых файлах. Начальник его отдела в Bell Labs, Дуг Макилрой, подошел к Томпсону и описал проблему одному из его коллег: Ли МакМахон, столкнулся.
МакМахон пытался установить авторов Федералистские документы посредством текстового анализа. Ему нужен был инструмент, который мог бы искать фразы и строки в текстовых файлах. В тот вечер Томпсон потратил около часа на превращение своего инструмента в универсальную утилиту, которую могли бы использовать другие, и переименовал его в grep. Он взял имя из командной строки ed g / re / p, что переводится как «глобальный поиск по регулярному выражению».
Вы можете смотреть, как говорит Томпсон к Брайан Керниган о рождении grep.
Простой поиск с помощью grep
Чтобы найти строку в файле, передайте поисковый запрос и имя файла в командной строке:

Отображаются совпадающие линии. В данном случае это одна строка. Соответствующий текст выделен. Это связано с тем, что в большинстве дистрибутивов grep имеет псевдоним:
alias grep='grep --colour=auto'
Давайте посмотрим на результаты, в которых есть несколько совпадающих строк. Мы будем искать слово «Среднее» в файле журнала приложения. Поскольку мы не можем вспомнить, находится ли слово в нижнем регистре в файле журнала, мы будем использовать параметр -i (игнорировать регистр):
grep -i Average geek-1.log

Отображаются все совпадающие строки, в каждой из которых выделяется соответствующий текст.

Мы можем отобразить несовпадающие строки, используя параметр -v (инвертировать совпадение).
grep -v Mem geek-1.log

Нет выделения, потому что это несовпадающие строки.
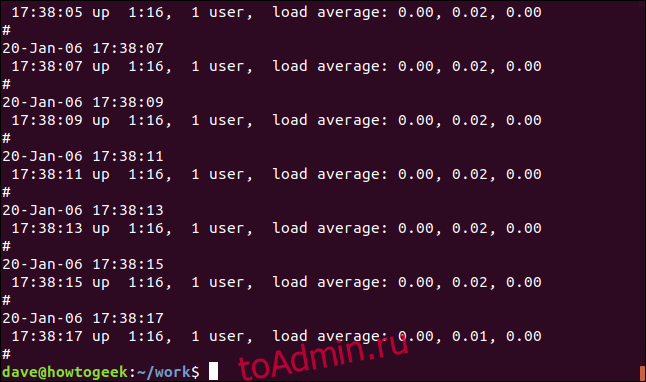
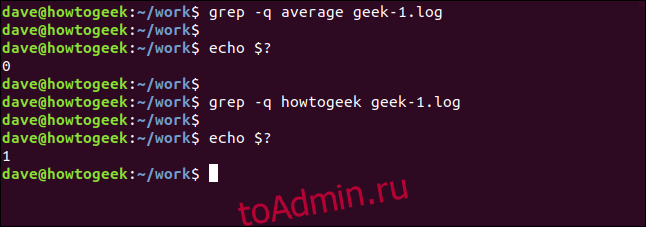
Мы можем заставить grep полностью молчать. Результат передается в оболочку как возвращаемое значение от grep. Нулевой результат означает, что строка была найдена, а результат, равный единице, означает, что она не найдена. Мы можем проверить код возврата с помощью символа $? специальные параметры:
grep -q average geek-1.log
echo $?
grep -q howtogeek geek-1.log
echo $?
Рекурсивный поиск с помощью grep
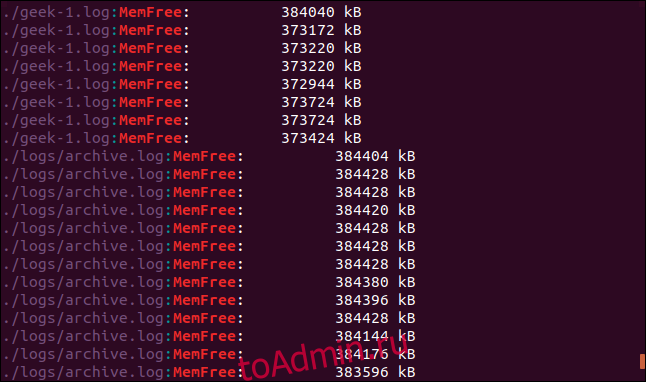
Для поиска во вложенных каталогах и подкаталогах используйте параметр -r (рекурсивный). Обратите внимание, что вы не указываете имя файла в командной строке, вы должны указать путь. Здесь мы ищем в текущем каталоге «.» и любые подкаталоги:
grep -r -i memfree .

Вывод включает каталог и имя файла каждой совпадающей строки.
Мы можем заставить grep следовать символическим ссылкам с помощью параметра -R (рекурсивное разыменование). В этом каталоге есть символическая ссылка, которая называется папка журналов. Он указывает на / home / dave / logs.
ls -l logs-folder

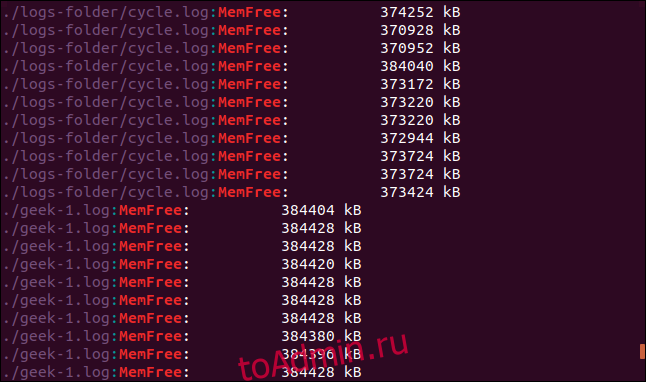
Повторим наш последний поиск с опцией -R (рекурсивное разыменование):
grep -R -i memfree .

По символической ссылке выполняется поиск по каталогу, на который она указывает.
Поиск целых слов
По умолчанию grep будет соответствовать строке, если цель поиска появляется где-нибудь в этой строке, в том числе внутри другой строки. Взгляните на этот пример. Мы будем искать слово «бесплатно».
grep -i free geek-1.log

Результатом являются строки, в которых есть «свободная» строка, но это не отдельные слова. Они являются частью строки «MemFree».

Чтобы заставить grep сопоставлять только отдельные «слова», используйте параметр -w (word regexp).
grep -w -i free geek-1.log
echo $?

На этот раз результатов нет, потому что поисковый запрос «бесплатно» не отображается в файле как отдельное слово.
Использование нескольких поисковых запросов
Параметр -E (расширенное регулярное выражение) позволяет искать несколько слов. (Параметр -E заменяет устаревший egrep версия grep.)
Эта команда выполняет поиск двух условий поиска: «средний» и «без памяти».
grep -E -w -i "average|memfree" geek-1.log

Все совпадающие строки отображаются для каждого условия поиска.
Вы также можете искать несколько терминов, которые не обязательно являются целыми словами, но могут быть и целыми словами.
Параметр -e (шаблоны) позволяет использовать несколько условий поиска в командной строке. Мы используем функцию скобок регулярного выражения для создания шаблона поиска. Он сообщает grep, что нужно сопоставить любой из символов, содержащихся в скобках «[]. » Это означает, что при поиске grep будет соответствовать либо «kB», либо «KB».
![grep -e MemFree -e [kK]B geek-1.log в окне терминала](https://toadmin.ru/wp-content/uploads/2021/01/1610843059_191_Как-использовать-команду-grep-в-Linux.png)
Обе строки совпадают, и на самом деле некоторые строки содержат обе строки.
![Вывод команды grep -e MemFree -e [kK]B geek-1.log в окне терминала](https://toadmin.ru/wp-content/uploads/2021/01/1610843059_155_Как-использовать-команду-grep-в-Linux.png)
Точное совпадение строк
-X (регулярное выражение строки) будет соответствовать только строкам, где вся строка соответствует поисковому запросу. Давайте поищем метку даты и времени, которая, как мы знаем, появляется в файле журнала только один раз:
grep -x "20-Jan--06 15:24:35" geek-1.log

Найдена и отображена единственная совпадающая строка.
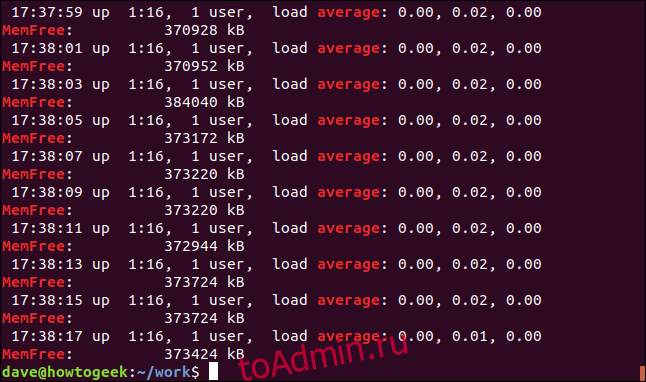
Противоположность этому показывает только несовпадающие строки. Это может быть полезно, когда вы просматриваете файлы конфигурации. Комментарии — это здорово, но иногда среди них сложно выделить настоящие настройки. Вот файл / etc / sudoers:

Мы можем эффективно отфильтровать строки комментариев следующим образом:
sudo grep -v "https://www.howtogeek.com/496056/how-to-use-the-grep-command-on-linux/#" /etc/sudoers
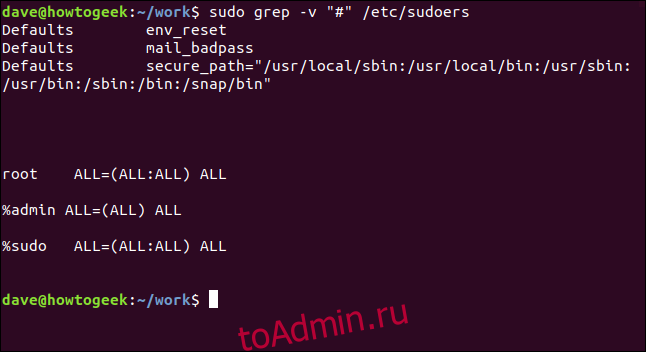
Это намного проще разобрать.
Отображается только соответствующий текст
Может быть случай, когда вы не хотите видеть всю совпадающую строку, а только соответствующий текст. Параметр -o (только соответствие) делает именно это.
grep -o MemFree geek-1.log

Отображение уменьшено до отображения только текста, соответствующего поисковому запросу, вместо всей соответствующей строки.

Подсчет с помощью grep
grep — это не только текст, он также может предоставлять числовую информацию. Мы можем подсчитывать grep по-разному. Если мы хотим знать, сколько раз поисковый запрос встречается в файле, мы можем использовать параметр -c (count).
grep -c average geek-1.log

grep сообщает, что поисковый запрос встречается в этом файле 240 раз.
Вы можете заставить grep отображать номер строки для каждой совпадающей строки, используя параметр -n (номер строки).
grep -n Jan geek-1.log

Номер строки для каждой совпадающей строки отображается в начале строки.
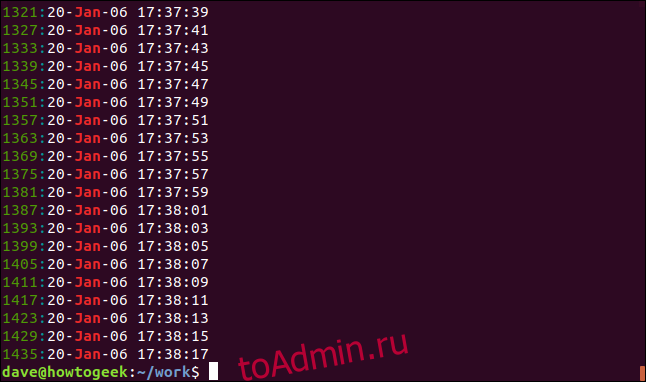
Чтобы уменьшить количество отображаемых результатов, используйте параметр -m (максимальное количество). Мы собираемся ограничить вывод пятью совпадающими строками:
grep -m5 -n Jan geek-1.log

Добавление контекста
Часто бывает полезно видеть некоторые дополнительные строки — возможно, несовпадающие — для каждой совпадающей строки. это может помочь определить, какие из совпадающих строк вам интересны.
Чтобы отобразить несколько строк после совпадающей строки, используйте параметр -A (после контекста). В этом примере мы просим три строчки:
grep -A 3 -x "20-Jan-06 15:24:35" geek-1.log
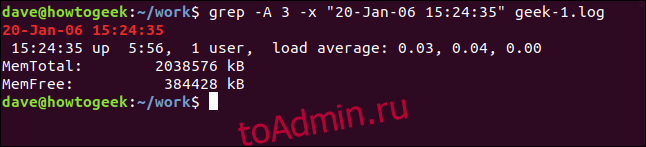
Чтобы увидеть некоторые строки перед совпадающей строкой, используйте параметр -B (контекст перед).
grep -B 3 -x "20-Jan-06 15:24:35" geek-1.log

А чтобы включить строки до и после совпадающей строки, используйте параметр -C (context).
grep -C 3 -x "20-Jan-06 15:24:35" geek-1.log

Отображение совпадающих файлов
Чтобы увидеть имена файлов, содержащих поисковый запрос, используйте параметр -l (файлы с совпадениями). Чтобы узнать, какие файлы исходного кода C содержат ссылки на файл заголовка sl.h, используйте эту команду:
grep -l "sl.h" *.c

В списке указаны имена файлов, а не совпадающие строки.

И, конечно же, мы можем искать файлы, которые не содержат поискового запроса. Параметр -L (файлы без совпадений) делает именно это.
grep -L "sl.h" *.c

Начало и конец строк
Мы можем заставить grep отображать только те совпадения, которые находятся либо в начале, либо в конце строки. Оператор регулярного выражения «^» соответствует началу строки. Практически все строки в файле журнала будут содержать пробелы, но мы собираемся искать строки, в которых пробел является первым символом:
grep "^ " geek-1.log

Отображаются строки с пробелом в качестве первого символа — в начале строки.

Чтобы соответствовать концу строки, используйте оператор регулярного выражения «$». Мы будем искать строки, заканчивающиеся на «00».
grep "00$" geek-1.log

На дисплее отображаются строки, в конце которых указано «00».

Использование каналов с grep
Конечно, вы можете направить ввод в grep, передать вывод из grep в другую программу и разместить grep в середине цепочки каналов.
Допустим, мы хотим видеть все вхождения строки «ExtractParameters» в наших файлах исходного кода C. Мы знаем, что их будет довольно много, поэтому мы направляем вывод в less:
grep "ExtractParameters" *.c | less

Результат представлен в меньшем количестве.
Это позволяет пролистывать список файлов и использовать поисковые возможности less.
Если мы передаем вывод grep в wc и используем параметр -l (lines), мы может подсчитать количество строк в файлах исходного кода, содержащих «ExtractParameters». (Мы могли бы добиться этого, используя опцию grep -c (count), но это отличный способ продемонстрировать конвейерное соединение с grep.)
grep "ExtractParameters" *.c | wc -l

С помощью следующей команды мы передаем вывод из ls в grep, а вывод из grep — в sort. Мы перечисляем файлы в текущем каталоге, выбирая те, в которых есть строка «Aug», и сортировка по размеру файла:
ls -l | grep "Aug" | sort +4n

Давайте разберемся с этим:
ls -l: выполнить длинный список форматов файлов с помощью ls.
grep «Aug»: выберите строки из списка ls, в которых есть «Aug». Обратите внимание, что при этом также будут найдены файлы, в именах которых есть «Aug».
sort + 4n: отсортировать вывод grep по четвертому столбцу (размер файла).
Мы получаем отсортированный список всех файлов, измененных в августе (независимо от года), в порядке возрастания размера файла.
grep: меньше команды, больше союзника
grep — отличный инструмент в вашем распоряжении. Он датируется 1974 годом и до сих пор пользуется успехом, потому что нам нужно то, что он делает, и ничто не делает это лучше.
Сочетание grep с некоторыми регулярными выражениями-fu действительно выводит его на новый уровень.