
Узнайте все, что вам нужно знать об исследовательском анализе данных, важном процессе, используемом для обнаружения тенденций и закономерностей и обобщения наборов данных с помощью статистических сводок и графических представлений.
Как и любой проект, проект по науке о данных — это длительный процесс, требующий времени, хорошей организации и скрупулезного соблюдения нескольких этапов. Исследовательский анализ данных (EDA) является одним из наиболее важных шагов в этом процессе.
Поэтому в этой статье мы кратко рассмотрим, что такое исследовательский анализ данных и как его можно выполнить с помощью R!
Оглавление
Что такое исследовательский анализ данных?
Исследовательский анализ данных исследует и изучает характеристики набора данных до того, как он будет отправлен в приложение, будь то исключительно деловое, статистическое или машинное обучение.
Это обобщение характера информации и ее основных особенностей обычно делается визуальными методами, такими как графическое представление и таблицы. Практика проводится заранее именно для оценки потенциала этих данных, которые в дальнейшем получат более сложную обработку.
Таким образом, EDA позволяет:
- Сформулировать гипотезы использования этой информации;
- Исследуйте скрытые детали в структуре данных;
- Выявление отсутствующих значений, выбросов или ненормального поведения;
- Откройте для себя тенденции и соответствующие переменные в целом;
- Отбросьте нерелевантные переменные или переменные, коррелирующие с другими;
- Определите используемое формальное моделирование.
В чем разница между описательным и исследовательским анализом данных?
Существует два типа анализа данных, описательный анализ и исследовательский анализ данных, которые идут рука об руку, несмотря на разные цели.
В то время как первый фокусируется на описании поведения переменных, например, среднего, медианы, моды и т. д.
Исследовательский анализ направлен на выявление взаимосвязей между переменными, извлечение предварительных сведений и направление моделирования на наиболее распространенные парадигмы машинного обучения: классификацию, регрессию и кластеризацию.
В целом оба могут иметь дело с графическим представлением; тем не менее, только исследовательский анализ направлен на то, чтобы дать полезные идеи, то есть идеи, которые провоцируют действия со стороны лица, принимающего решения.
Наконец, в то время как исследовательский анализ данных направлен на решение проблем и поиск решений, которые будут направлять этапы моделирования, описательный анализ, как следует из его названия, направлен только на получение подробного описания рассматриваемого набора данных.
Описательный анализИсследовательский анализ данныхАнализирует поведениеАнализирует поведение и отношенияПредоставляет сводку Приводит к спецификации и действиямОрганизует данные в таблицы и графикиОрганизует данные в таблицы и графикиНе обладает значительной объяснительной силойИмеет значительную объяснительную силу
Некоторые практические примеры использования EDA
№1. Цифровой маркетинг
Цифровой маркетинг превратился из творческого процесса в процесс, управляемый данными. Маркетинговые организации используют исследовательский анализ данных для определения результатов кампаний или усилий, а также для управления инвестициями потребителей и решениями о таргетинге.
Демографические исследования, сегментация клиентов и другие методы позволяют маркетологам использовать большие объемы потребительских покупок, опросов и панельных данных для понимания и передачи стратегии маркетинга.
Исследовательская веб-аналитика позволяет маркетологам собирать информацию о взаимодействиях на веб-сайте на уровне сеанса. Google Analytics является примером бесплатного и популярного инструмента аналитики, который маркетологи используют для этой цели.
Исследовательские методы, часто используемые в маркетинге, включают моделирование маркетингового комплекса, анализ ценообразования и продвижения, оптимизацию продаж и исследовательский анализ клиентов, например, сегментацию.
№ 2. Исследовательский анализ портфеля
Распространенным применением исследовательского анализа данных является исследовательский анализ портфеля. Банк или кредитное агентство имеет набор счетов различной стоимости и риска.
Аккаунты могут различаться в зависимости от социального статуса владельца (богатый, средний класс, бедный и т. д.), географического положения, состояния и многих других факторов. Кредитор должен сбалансировать прибыль по кредиту с риском дефолта по каждому кредиту. Тогда возникает вопрос, как оценить портфель в целом.
Кредит с наименьшим риском может быть для очень богатых людей, но есть очень ограниченное количество богатых людей. С другой стороны, многие бедняки могут давать взаймы, но с большим риском.
Решение для исследовательского анализа данных может сочетать анализ временных рядов со многими другими проблемами, чтобы решить, когда ссужать деньги этим различным сегментам заемщиков или ставке ссуды. Проценты начисляются участникам сегмента портфеля для покрытия убытков участников этого сегмента.
№3. Исследовательский анализ рисков
Прогностические модели в банковской сфере разрабатываются, чтобы обеспечить уверенность в оценках риска для отдельных клиентов. Кредитные баллы предназначены для прогнозирования делинквентного поведения человека и широко используются для оценки кредитоспособности каждого заявителя.
Кроме того, анализ рисков проводится в научном мире и страховой отрасли. Он также широко используется в финансовых учреждениях, таких как компании-шлюзы онлайн-платежей, для анализа того, является ли транзакция подлинной или мошеннической.
Для этого они используют историю транзакций клиента. Он чаще используется при покупках по кредитным картам; когда происходит внезапный всплеск объема транзакций клиента, клиент получает звонок с подтверждением, если он инициировал транзакцию. Это также помогает уменьшить потери из-за таких обстоятельств.
Исследовательский анализ данных с помощью R
Первое, что вам нужно для выполнения EDA с R, — это загрузить R base и R Studio (IDE), а затем установить и загрузить следующие пакеты:
#Installing Packages
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
#Loading Packages
library(dplyr)
library(ggplot2)
library(magrittr)
library(tsibble)
library(forecast)
library(skimr)
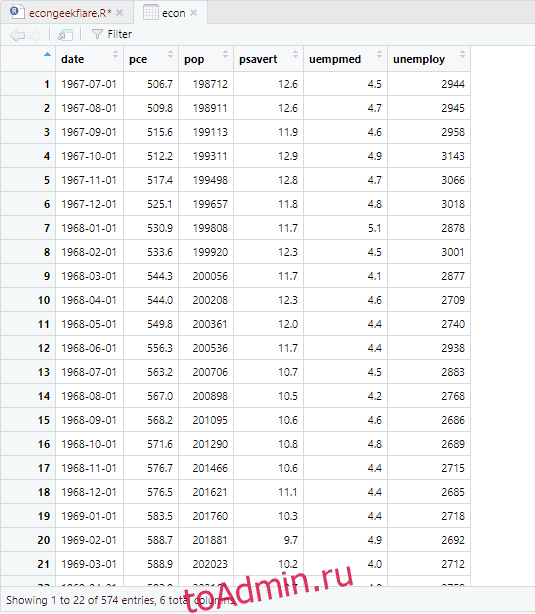
В этом руководстве мы будем использовать набор экономических данных, встроенный в R и предоставляющий ежегодные данные экономических показателей экономики США, и для простоты изменим его название на econ:
econ <- ggplot2::economics
Чтобы выполнить описательный анализ, мы будем использовать пакет skimr, который вычисляет эту статистику простым и хорошо представленным способом:
#Descriptive Analysis skimr::skim(econ)

Вы также можете использовать функцию сводки для описательного анализа:
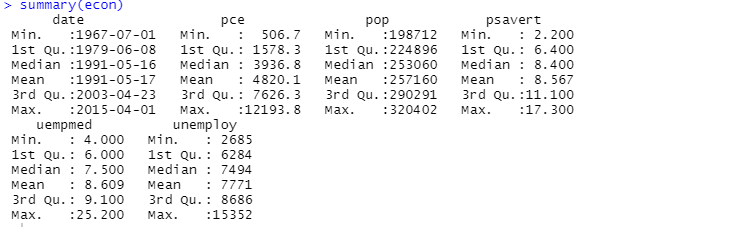
Здесь описательный анализ показывает 547 строк и 6 столбцов в наборе данных. Минимальное значение — 01.07.1967, максимальное — 01.04.2015. Точно так же он также показывает среднее значение и стандартное отклонение.
Теперь у вас есть общее представление о том, что находится внутри набора экономических данных. Давайте построим гистограмму переменной uempmed, чтобы лучше рассмотреть данные:
#Histogram of Unemployment econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Unemployment", title = "Monthly Unemployment Rate in US between 1967 to 2015")
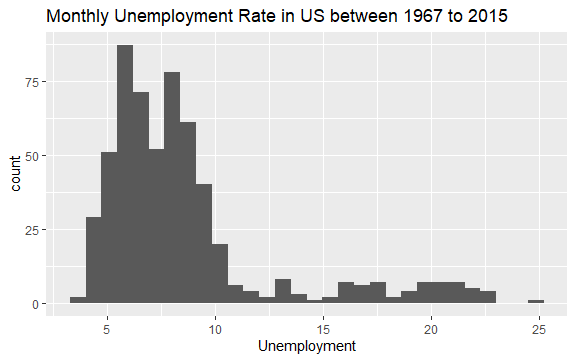
Распределение гистограммы показывает, что она имеет удлиненный хвост справа; то есть, возможно, есть несколько наблюдений этой переменной с более «экстремальными» значениями. Возникает вопрос: в какой период имели место эти значения и каков тренд переменной?
Самый прямой способ определить тенденцию переменной — это линейный график. Ниже мы создаем линейный график и добавляем линию сглаживания:
#Line Graph of Unemployment econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth()
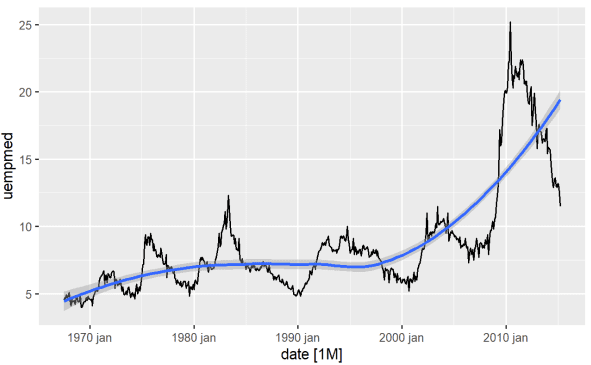
Используя этот график, мы можем выявить, что в самый последний период, в последние наблюдения с 2010 года, наблюдается тенденция роста безработицы, превосходящая историю, наблюдавшуюся в предыдущие десятилетия.
Еще одним важным моментом, особенно в контексте эконометрического моделирования, является стационарность ряда; то есть являются ли среднее значение и дисперсия постоянными во времени?
Когда эти предположения неверны для переменной, мы говорим, что ряд имеет единичный корень (нестационарный), так что шоки, которым подвергается переменная, вызывают постоянный эффект.
По-видимому, это имело место в отношении рассматриваемой переменной, продолжительности безработицы. Мы видели, что колебания переменной значительно изменились, что имеет серьезные последствия, связанные с экономическими теориями, имеющими дело с циклами. Но, отступая от теории, как практически проверить, является ли переменная стационарной?
В пакете прогнозов есть отличная функция, позволяющая применять тесты, такие как АДФ, КПСС и другие, которые уже возвращают количество разностей, необходимое для того, чтобы ряд был стационарным:
#Using ADF test for checking stationarity forecast::ndiffs( x = econ$uempmed, test = "adf")

Здесь p-значение больше 0,05 показывает, что данные нестационарны.
Другой важной проблемой временных рядов является выявление возможных корреляций (линейных отношений) между лаговыми значениями ряда. Выявить его помогают коррелограммы ACF и PACF.
Поскольку ряд не имеет сезонности, а имеет определенную тенденцию, начальные автокорреляции имеют тенденцию быть большими и положительными, поскольку близкие по времени наблюдения также близки по значению.
Таким образом, автокорреляционная функция (АКФ) трендового временного ряда имеет тенденцию иметь положительные значения, которые медленно уменьшаются по мере увеличения лагов.
#Residuals of Unemployment checkresiduals(econ$uempmed) pacf(econ$uempmed)
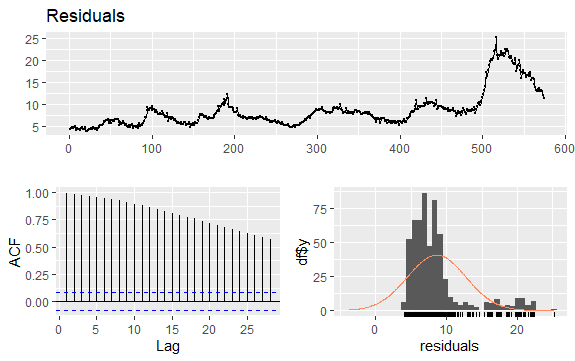
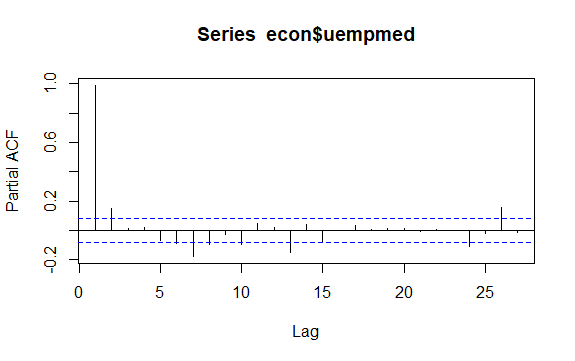
Вывод
Когда мы получаем более или менее чистые данные, то есть уже очищенные, у нас сразу возникает соблазн погрузиться в стадию построения модели, чтобы получить первые результаты. Вы должны сопротивляться этому искушению и начать проводить исследовательский анализ данных, который прост, но помогает нам извлечь из данных ценную информацию.
Вы также можете изучить некоторые лучшие ресурсы для изучения статистики для науки о данных.